TAGora Applications
Collaborative tagging originated from the need to manage large collections of data. Tagging data is a means to describe, search, and retrieve objects in an intuitive way, which constitutes an important factor of its success. TAGora will provide experimental systems which are on the one hand intended to further improve navigation possibilities provided by tags, and on the other hand deliver data for the research work of the project. In order to have privileged and controllable data sources for the collaboration, TAGora plans to design and deploy systems – both online systems and actual demonstrations/experiments – for the specific purpose of data collection.
BibSonomy
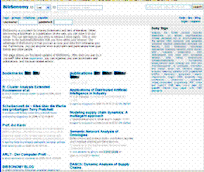 The Hertie Chair of “Knowledge & Data Engineering” has been developing a Social Bookmark System, called Bibsonomy, which allows users to upload their bookmarks or bibliographic references and assign them arbitrary labels, denoted “tags”. BibSonomy allows users to share bookmarks and publication references. In general, social resource sharing systems all use the same kind of lightweight knowledge representation, called folksonomy. The word “folksonomy” is a merge of the words “folk” and “taxonomy”, and stands for the conceptual structure of knowledge created by people. By assigning a list of tags to a resource, each user builds up a so called “personomy”. The user can explore his own personomy, as well as the personomies of different users.
The Hertie Chair of “Knowledge & Data Engineering” has been developing a Social Bookmark System, called Bibsonomy, which allows users to upload their bookmarks or bibliographic references and assign them arbitrary labels, denoted “tags”. BibSonomy allows users to share bookmarks and publication references. In general, social resource sharing systems all use the same kind of lightweight knowledge representation, called folksonomy. The word “folksonomy” is a merge of the words “folk” and “taxonomy”, and stands for the conceptual structure of knowledge created by people. By assigning a list of tags to a resource, each user builds up a so called “personomy”. The user can explore his own personomy, as well as the personomies of different users.
With such a system, run by a project partner, we will have unfettered access to the complete data, the possibility of tracking the full temporal evolution of the system, from the very beginning, and the possibility to directly observe the influence of different parameter settings. The latter includes the option to analyse the effect of more sophisticated knowledge representations, like hierarchically structured personomies, binary relations between resources (as known from the semantic web), or statistical relationships indicating the degree of similarities of the content of different personomies. This provides the possibility to directly observe on a large natural user group the influence of knowledge representation decisions on the structure and evolution of the social network. An existing prototype offers the basic features for social tagging, but does not yet provide the functionality of the systems above, nor does it provide exclusive functionality. For attracting a larger set of users, and thus obtaining significant benchmark data, we will have to provide extended features, as well as a scalable implementation and a component for systematic data collection. On these data, we will study the structure of the emerging network, in particular its topological properties, dynamical properties, and clustering/social properties.
Ikoru
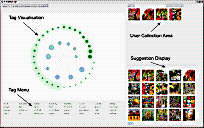 Ikoru is a prototypical system developed by Sony CSL that unifies browsing by tags and visual features. This combination allows an intuitive exploration of databases and helps to overcome shortcomings of solely tag-based systems. In contrast to traditional image retrieval approaches, Ikoru employs user tags, complemented by image analysis and classification. The image analysis in Ikoru is based on simple global features. Rather than trying to recognize objects or even explain the meaning of an image, Ikoru seeks to measure a certain “atmosphere”, or a vague visual pattern, which can be captured by low level image features such as colour or texture. Sony CSL plans to develop a similar system for music data as well.
Ikoru is a prototypical system developed by Sony CSL that unifies browsing by tags and visual features. This combination allows an intuitive exploration of databases and helps to overcome shortcomings of solely tag-based systems. In contrast to traditional image retrieval approaches, Ikoru employs user tags, complemented by image analysis and classification. The image analysis in Ikoru is based on simple global features. Rather than trying to recognize objects or even explain the meaning of an image, Ikoru seeks to measure a certain “atmosphere”, or a vague visual pattern, which can be captured by low level image features such as colour or texture. Sony CSL plans to develop a similar system for music data as well.
Ikoru also serves as a platform for further experiments. For example, the relation between data features and tags will be investigated. We observe that only a fraction of tags can be grounded, e.g. low-level tags such as “red”, or “blackandwhite” for images, and “loud” or “fast” for music. We expect that a simple one-to-one mapping from a tag to a category that can be described in terms of data features is only possible for these low-level tags. High-level tags such as “abandoned”, “decay”, tags denoting locations such as “Paris”, or tags denoting persons will not show the same behaviour. We will thus investigate possibilities to achieve an indirect grounding, e.g. by exploiting the co-occurrence relation between high-level and low-level tags. The findings of these experiments will then be used to implement tag proposition into our systems, in order to assist the user in the tedious process of tagging. This mechanism will allow us to study the influence of tag suggestions on convergence properties as well as on the precision of tagging.
Zexe
 canal*MOTOBOY and GENEVE*accessible are the latest projects of the zexe.net initiative. Both of these projects make an intensive use of tagging. In canal*MOTOBOY, 15 motorcycle messengers in Sao Paulo, Brazil, use multimedia mobile phones to capture images and videos of their daily life. They use tags to describe these contents, which they publish on the web. The GENEVE*accessible project involves handicapped people in Geneva, Switzerland. They use multimedia phones equipped with GPS to create maps of their city’s accessibility. They use tags to describe the images of obstacles they find in their way. By publishing these tagged and geo-referenced images on the web, they effectively build an intelligent, collaborative map which is immediately available to the public. Both groups have benefitted from the projects since they have allowed the participants to represent and communicate their particular issues. These projects have enabled members of TAGora to study the dynamics of tagging in small-scale groups with shared interests.
canal*MOTOBOY and GENEVE*accessible are the latest projects of the zexe.net initiative. Both of these projects make an intensive use of tagging. In canal*MOTOBOY, 15 motorcycle messengers in Sao Paulo, Brazil, use multimedia mobile phones to capture images and videos of their daily life. They use tags to describe these contents, which they publish on the web. The GENEVE*accessible project involves handicapped people in Geneva, Switzerland. They use multimedia phones equipped with GPS to create maps of their city’s accessibility. They use tags to describe the images of obstacles they find in their way. By publishing these tagged and geo-referenced images on the web, they effectively build an intelligent, collaborative map which is immediately available to the public. Both groups have benefitted from the projects since they have allowed the participants to represent and communicate their particular issues. These projects have enabled members of TAGora to study the dynamics of tagging in small-scale groups with shared interests.
Tagster
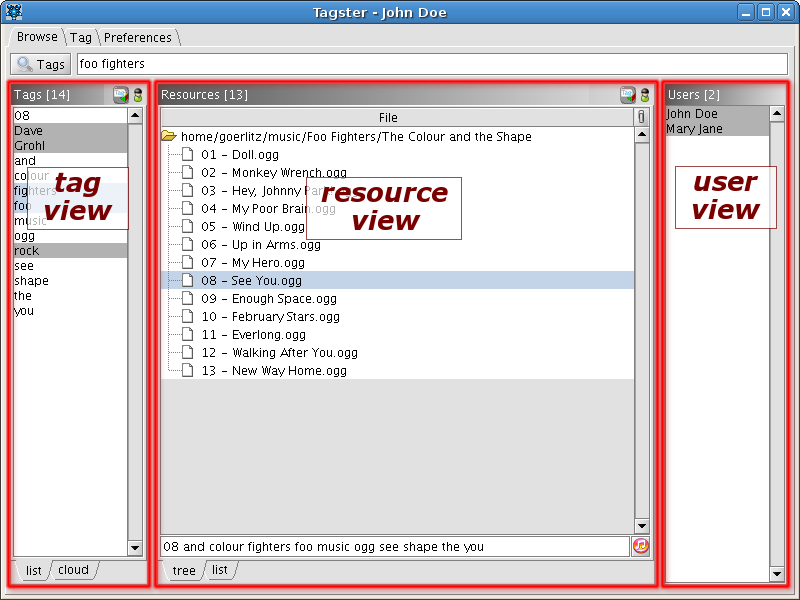 Tagster is a peer-to-peer tagging application. Very much like Flickr, Del.icio.us, Bibsonomy etc. it allows to tag and share personal data. But instead of uploading the data to such an internet service, Tagster organizes and stores everything on the local computer. Therefore, unlike previous examples, Tagster can collect tagged resources of any format. It is based on a modular architecture, formerly known as the Semantic Exchange architecture (SEA). All tagged data are publicly available for the whole network and there is no mechanism to prevent the publication or to mark something as private data. The prototype is currently only available on request. Please send an email to Olaf Görlitz to receive the login information. The platform-independent version of Tagster can be downloaded via the project website. The knowledge of global statistics about tagging data extracted by Tagster is useful for different purposes. The next steps in the development of Tagster will include the collection of experience data from Tagster use, sophisticated means for recommending resources from the distributed peers, and additional wrappers for facilitating data collection from further semantic and non-semantic sources. With such support Tagster may offer a viable open alternative to closed, centralized systems. The long-term objective is the efficient and effective infrastructure for decen- tralized, self-organizing Web 2.0 applications which allows for scalable sharing, annotation, searching, and browsing of relevant resources. Click on the image to view a screenshot of Tagster.
Tagster is a peer-to-peer tagging application. Very much like Flickr, Del.icio.us, Bibsonomy etc. it allows to tag and share personal data. But instead of uploading the data to such an internet service, Tagster organizes and stores everything on the local computer. Therefore, unlike previous examples, Tagster can collect tagged resources of any format. It is based on a modular architecture, formerly known as the Semantic Exchange architecture (SEA). All tagged data are publicly available for the whole network and there is no mechanism to prevent the publication or to mark something as private data. The prototype is currently only available on request. Please send an email to Olaf Görlitz to receive the login information. The platform-independent version of Tagster can be downloaded via the project website. The knowledge of global statistics about tagging data extracted by Tagster is useful for different purposes. The next steps in the development of Tagster will include the collection of experience data from Tagster use, sophisticated means for recommending resources from the distributed peers, and additional wrappers for facilitating data collection from further semantic and non-semantic sources. With such support Tagster may offer a viable open alternative to closed, centralized systems. The long-term objective is the efficient and effective infrastructure for decen- tralized, self-organizing Web 2.0 applications which allows for scalable sharing, annotation, searching, and browsing of relevant resources. Click on the image to view a screenshot of Tagster.
MyTag
 MyTag aims at solving the limitations of current tagging platforms by enabling cross-media search across images, video, and social bookmarks. It offers transparent access to different single-media platforms currently including Flickr, YouTube, and del.icio.us. The search function can be personalized in two directions. First, MyTag users can restrict the search to the resources uploaded by the user him/herself. Second, the website uses an implicit user feedback mechanism to personalize the output of a query to MyTag by ranking results according to the user’s personomy. The personomy is built without additional effort by the previous queries entered by the user, in contrast with other tagging platforms, such as Flickr or del.icio.us, where an explicit feedback is required in order to personalize the ranking of the results presented to the user. More information about the architecture of MyTag can be found in the paper “Personalized Search and Exploration with MyTag”.
MyTag aims at solving the limitations of current tagging platforms by enabling cross-media search across images, video, and social bookmarks. It offers transparent access to different single-media platforms currently including Flickr, YouTube, and del.icio.us. The search function can be personalized in two directions. First, MyTag users can restrict the search to the resources uploaded by the user him/herself. Second, the website uses an implicit user feedback mechanism to personalize the output of a query to MyTag by ranking results according to the user’s personomy. The personomy is built without additional effort by the previous queries entered by the user, in contrast with other tagging platforms, such as Flickr or del.icio.us, where an explicit feedback is required in order to personalize the ranking of the results presented to the user. More information about the architecture of MyTag can be found in the paper “Personalized Search and Exploration with MyTag”.
TAGora project started on June 1st 2006
Sixth Framework Programme, Information Society Technologies, IST call 5, Contract N. 34721
Powered by WordPress |
Entries and comments feeds |
Valid XHTML and CSS